
In brief
- Xiaomi and inference partner TileRT have broken 1,000 tokens per second on a 1-trillion-parameter model, a first at that scale, using a standard 8-GPU commodity node—not custom chips.
- The speed comes from FP4 quantization on the model’s expert layers and DFlash speculative decoding, which proposes a full block of tokens in one pass instead of one at a time.
- A limited API trial opens June 9 through June 23, priced at 3× standard MiMo rates for roughly 10× the generation speed.
Most people know Xiaomi as the Chinese phone brand. The one that makes cheap electric scooters and air purifiers. Not exactly the company you’d expect to break a major AI inference speed record on a Monday morning.
And yet. Xiaomi just released MiMo-V2.5-Pro-UltraSpeed, a serving mode for its trillion-parameter flagship that hits over 1,000 tokens per second—peaking near 1,200 in demos.
Parameters are the internal numerical weights that define how a model thinks—the more you have, the more complex the patterns it can recognize. Tokens are the chunks of text the model reads and writes, roughly three-quarters of a word each on average.
Xiaomi did it on a single 8-GPU commodity node. Standard hardware, no custom chips. That changes the calculus for who can actually deploy this kind of speed in production.
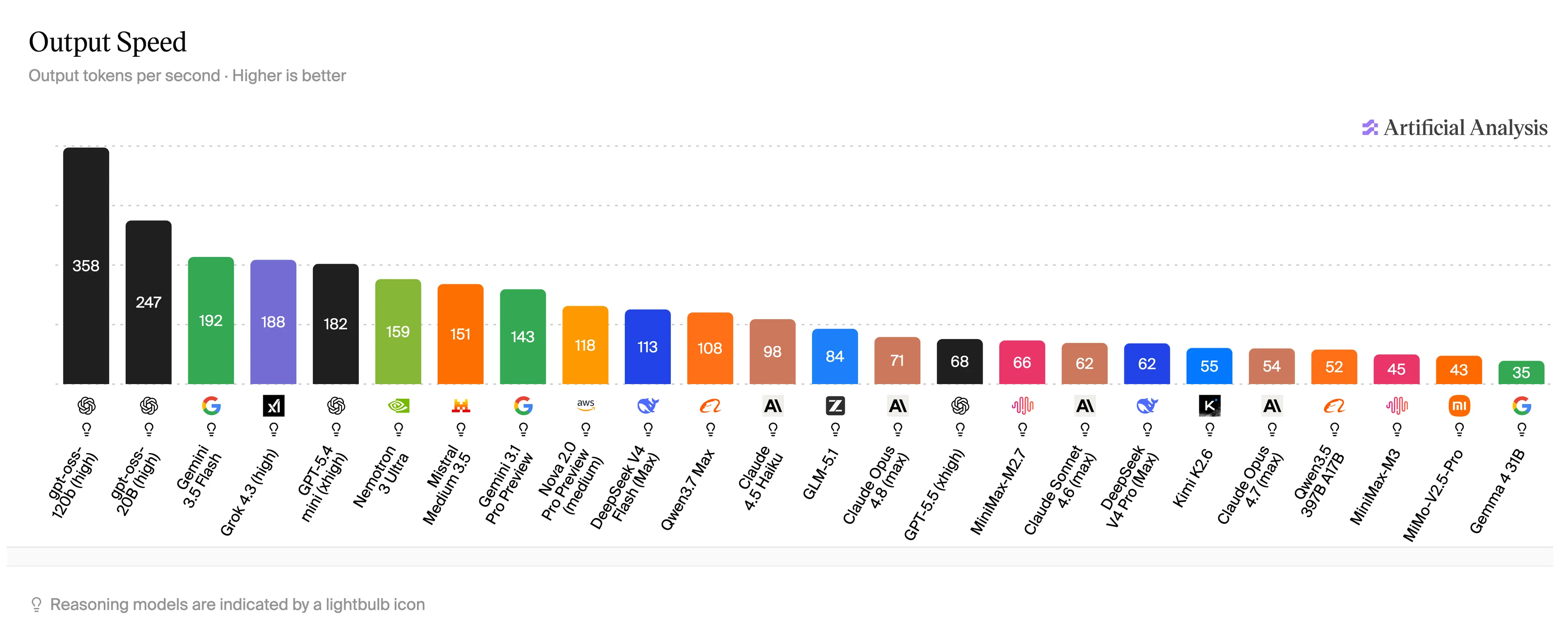
To put that number in human terms: per Artificial Analysis, GPT-5.5—what most ChatGPT users are actually talking to—sits at 68. Claude Opus 4.6 lands around 71 with the lower end model, Haiku, touching 98 tokens per second. Gemini Flash hits 192 tokens per second. MiMo-V2.5-Pro-UltraSpeed does 1,000, on a model that matches Opus on coding benchmarks.
Cerebras and Groq built entire businesses around this problem. Cerebras designed a wafer-scale chip the size of a dinner plate, packing 44GB of on-chip memory to eliminate the bandwidth bottleneck that slows down GPU inference. It hit 969 tokens per second on Meta’s Llama 3.1 405B—impressive, but that’s a 405-billion-parameter model, less than half the size of MiMo-V2.5-Pro. Groq’s custom Language Processing Unit architecture tops out around 300–750 tokens per second depending on model.
Neither runs on hardware you can rent from AWS tonight.
Xiaomi did it on commodity GPUs through software alone—a combination of model-level tricks and a purpose-built inference engine called TileRT.
What’s actually going on under the hood
Two techniques carry the speed. The first technique is called FP4 Quantization: instead of running the model at full 8-bit or 16-bit numerical precision, Xiaomi shrinks the expert layers—which make up most of the 1 trillion parameters—down to 4-bit. Memory footprint drops, bandwidth pressure drops, speed goes up. The catch is usually a small quality degradation. Xiaomi’s fix is surgical: only the expert layers get compressed, everything else stays at full precision. With this approach, quality loss is described as near-zero.
The second is DFlash speculative decoding. Normal speculative decoding has a small draft model guess the next few tokens, then the big model verifies them in parallel. DFlash skips the sequential drafting entirely—it fills a whole block of masked positions in a single forward pass. In coding tasks, the big model accepts an average of 6.3 out of 8 proposed tokens per verification round. That’s six tokens confirmed in one step instead of one.
TileRT ties it together. It keeps the entire compute pipeline continuously resident inside the GPU—no per-operator launch overhead, no execution gaps.
Xiaomi calls this approach “extreme model-system codesign,” and the phrase is accurate: Neither technique alone gets to 1,000 tokens per second, but the synergy among all approaches does.
MiMo-V2.5-Pro is a frontier-level model. We covered the V2.5 Pro launch in April—it matches Claude Opus on most coding benchmarks and runs at roughly $0.43 input / $0.87 output per million tokens. Opus costs $5 input / $25 output per million tokens.
UltraSpeed accelerates that exact MiMo V2.5 Pro model, not a stripped-down version.
Fast enough inference changes how you can use a model. You can run dozens of reasoning paths in parallel instead of waiting on one answer. Fraud detection, trading signal generation, real-time agent loops—all of these have hard latency constraints that 60 tokens per second can’t meet. At 1,000 tokens per second, they can.
Xiaomi is pricing the speed at 3 times the standard MiMo-V2.5-Pro rate for roughly 10 times the output. The API trial runs June 9–23, application-based, with priority given to enterprise and professional developers. The FP4-DFlash checkpoint is already open-sourced on Hugging Face for community testing.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.
Artificial Intelligence#China039s #Xiaomi #MiMo #15X #Faster #ChatGPT #Claude1780954190

{kind=link}